
In the vast landscape of website optimization and search engine ranking, understanding the nuances of a robots.txt file is crucial. This comprehensive guide will walk you through the essentials of robots.txt, from its basic structure to practical tips on setting up allow and disallow directives.
What is a Robots.txt File?
The robots.txt file, a seemingly unpretentious text document, unveils itself as a fundamental linchpin in the intricate realm of website optimization. Crafted by website proprietors as a conduit of communication with web crawlers, this unassuming file transforms into a potent orchestrator, deftly leading and channeling these digital wanderers through the labyrinth of a site. It stands as a virtual gatekeeper, a custodian of the website’s digital sanctity, whispering coded instructions to the inquisitive search engine bots. Beyond its apparent simplicity lies a profound influence, dictating not just which pages should be embraced into the expansive index but also, crucially, which segments should remain veiled, shielded from the algorithmic gaze. In essence, the robots.txt file transcends its textual modesty, assuming the role of a strategic conductor, guiding and shaping the symphony of search engine interactions that determine the fate of a website’s visibility in the vast expanse of the digital landscape.
Robots.txt Format:
The robots.txt file follows a standardized format that web crawlers recognize. It is a plain text file placed in the root directory of a website. The basic structure typically includes two main directives: User-agent and Disallow.
User-agent specifies the web crawler or user agent to which the directives apply. This allows for specific instructions tailored to different search engine bots or user agents. The Disallow directive, on the other hand, outlines the URLs or directories that should not be crawled.
What is Allow and Disallow in Robots.txt?
The terms “allow” and “disallow” in robots.txt serve as commands that dictate the access level of web crawlers to specific parts of a website. The “allow” directive permits a crawler to access and index a particular URL or directory, while the “disallow” directive restricts access, preventing indexing of the specified content.
Understanding the balance between “allow” and “disallow” is crucial for fine-tuning your website’s visibility on search engines. Striking the right balance ensures that essential content is accessible to crawlers while keeping sensitive or irrelevant information hidden.
Setting Up Allow and Disallow:
Crafting an effective robots.txt file requires a thoughtful approach. Begin by identifying the parts of your website that you want to make accessible to search engines and those you wish to keep private. Once identified, construct directives that align with these objectives.
For example, to allow access to all content, a simple directive like `User-agent: * Disallow:` can be used. On the other hand, specifying individual directives for different user agents allows for a more tailored approach, ensuring that each crawler interacts with your site appropriately.
Example 1: Allow All Crawlers Access to the Entire Site
If your aim is to grant unrestricted access to all parts of your website, a simple directive can be employed:
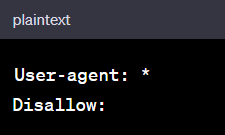
This straightforward command invites all web crawlers to freely explore and index every nook and cranny of your site.
Example 2: Allow Specific User Agents with Disallow for Certain Directories
For a more nuanced approach, you can tailor directives to individual user agents. Here’s an example that allows Googlebot access to your entire site while restricting Bingbot from a specific directory:
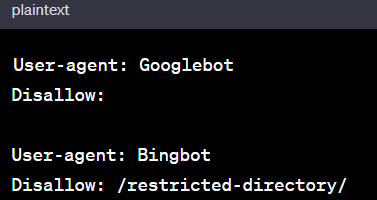
This ensures that Googlebot can freely explore, while Bingbot is gracefully steered away from the designated directory.
Example 3: Disallow Crawling of Certain File Types
To prevent web crawlers from accessing specific file types, such as PDFs or images, you can use the following:
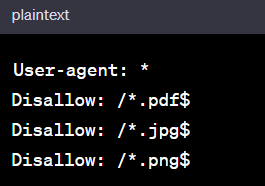
This set of directives communicates a clear message to all crawlers, restricting their access to files with the specified extensions.
By strategically employing “allow” and “disallow” directives, you can sculpt the landscape of crawler accessibility on your website, ensuring that search engines navigate and index your content in alignment with your site’s objectives.
Robots.txt Sitemap:
In addition to the traditional User-agent and Disallow directives, the robots.txt file can also include a reference to the website’s XML sitemap. This is done using the “Sitemap” directive. Including your sitemap in the robots.txt file provides search engine bots with a roadmap to efficiently crawl and index your site’s content.
A typical entry would look like this:
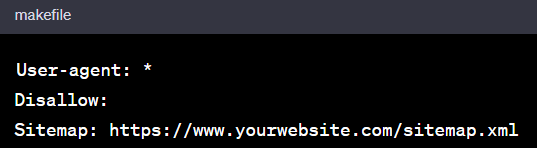
This informs all user agents that all parts of the website are accessible, and the sitemap is located at the specified URL.
Conclusion:
In the intricate world of search engine optimization (SEO), the robots.txt file stands as a fundamental tool to guide web crawlers through your website. Mastering its structure, understanding the nuances of “allow” and “disallow,” and incorporating the sitemap directive can significantly impact how search engines perceive and rank your content.
By harnessing the power of robots.txt, you empower yourself to shape the online visibility of your website, ensuring that search engines navigate your content with precision, ultimately leading to improved search rankings and a more streamlined user experience.


